
چگونه هوش مصنوعی به این دوقلو دیجیتال کمک می کند تا به شرکت های آب و شهروندان هیوستون کمک کند.
شهر هوستون و مقامات آب در منطقه پروژه ای چند ساله را برای ایجاد یک توسعه بزرگ در کارخانه تصفیه آب شمال شرقی (NEWPP) آغاز کرده اند. این پروژه ظرفیت را از 80 میلیون دلار به 400 میلیون دلار افزایش می دهد. با استفاده از سیستم پشتیبانی تصمیم گیری Blue Plan-it® Carollo، یک مدل عملیاتی دیجیتال-دوقلو برای NEWPP ایجاد شد تا به مهندسان، مدیران و اپراتورها کمک کند تا به طور مجازی با امکانات خود برای پشتیبانی از تصمیمات عملیاتی آزمایش کنند (شکل 1).
کالیبرهشده با استفاده از دادههای آزمایشی در مقیاس کامل، مقیاس آزمایشی و روی میز، دوقلو دیجیتال ما میتواند جریان و تعادل جرم را ردیابی کند، تولید جامدات و مصرف مواد شیمیایی را تخمین بزند، ترافیک کامیون مرتبط با حمل مواد شیمیایی و جامدات را شبیهسازی کند و مصرف برق را ارزیابی کند. با چندین تجزیه و تحلیل تصفیه آب مبتنی بر مکانیکی یکپارچه، می توان از آن برای ارزیابی غلظت-زمان (CT) و پیش بینی تشکیل محصول جانبی ضد عفونی (DBP) برای سیستم های چند ضد عفونی کننده گیاه، از جمله ازن، دی اکسید کلر، کلر، و کلرامین استفاده کرد. این می تواند اثرات افزودنی های شیمیایی را بر کیفیت آب شبیه سازی کند، 15 شاخص خوردگی و پایداری را با استفاده از الگوریتم های استاندارد مشابه الگوریتم های مورد استفاده در مدل RTW، مدل Water Pro، مدل EPA WTP و غیره ردیابی کند.
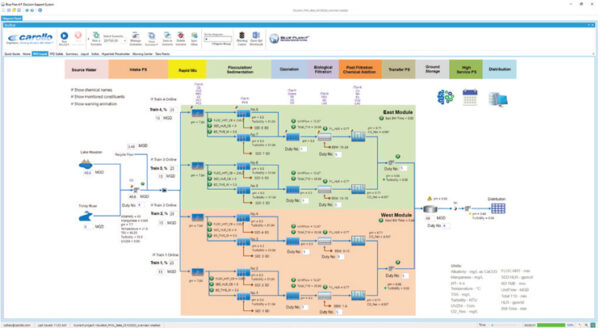
تصویر 1. شبیهساز عملیات WTP Blue Plan-it Carollo که با جدیدترین تجزیه و تحلیلهای یادگیری ماشین و هوش مصنوعی ادغام شده است به مدیران و اپراتورهای کارخانه تصفیه آب کمک میکند بهرهوری را افزایش دهند و هزینههای عملیاتی را کاهش دهند.
با این حال، یکی از حوزههای چالش برانگیز در مدلسازی تصفیه آب، چگونگی تخمین کدورت آب ته نشین شده و کل کربن آلی (TOC) با ترکیبی از مواد شیمیایی انعقاد/لختهسازی (آلومینیوم کلرآل هیدرات) است. [ACH]، کمک منعقد کننده، کمک لخته و غیره) اضافه می شود. هیچ مدل مکانیزم دقیقی برای شبیهسازی عملکرد فرآیند لختهسازی و رسوبگذاری در دسترس نیست. مدلهای تجربی اغلب از نظر قابلیتها و دقت محدود هستند، همانطور که در شکل 2 نشان داده شده است.
در گذشته، کارکنان کارخانه برای تعیین میزان حذف کدورت و TOC تحت یک طرح دوز شیمیایی معین به آزمایش روزانه شیشه تکیه می کردند. در سالهای اخیر، اندازهگیریهای پتانسیل زتا معرفی شدند که به نظر میرسید همبستگی بهتری با دوزهای شیمیایی داشتند. اما هنوز برای پشتیبانی از توسعه و کالیبراسیون یک مدل قابل اعتماد و قابل استفاده جهانی کافی نیست. یک ماژول پشتیبانی عملیات انعطاف پذیر برای کاربر مورد نظر است تا: 1) تعیین کیفیت آب ته نشین شده بر اساس کدورت خام و TOC همراه با دوز منعقد کننده و پلیمر. 2) تعیین دوزهای شیمیایی بر اساس کدورت خام و TOC و همچنین کیفیت آب ته نشین شده هدف. و 3) تعیین دوز منعقد کننده و پلیمرها بر اساس کیفیت آب خام و هدف پتانسیل زتا.
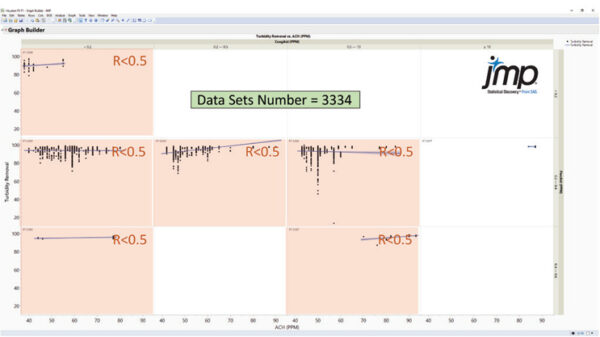
تصویر 2. تجزیه و تحلیل همبستگی چند منطقه ای داده های تاریخی نشان داد که دوزهای شیمیایی همبستگی ضعیفی با کدورت آب ته نشین شده و حذف TOC، با مقدار ضریب تعیین (R2) کمتر از 0.5 دارند.
در سال های اخیر، تجزیه و تحلیل داده های پیشرفته و فن آوری های یادگیری ماشینی محبوبیت فزاینده ای در صنعت آب به دست آورده اند. با استفاده از کتابخانههای محاسباتی رایج، کاربران میتوانند از یادگیری ماشین برای شناسایی الگوهای دادهها و تولید مدلهای آماری بدون دستورالعملهای صریح استفاده کنند. به طور کامل در مدلهای Blue Plan-it Digital Twin، چندین روش کدگذاری یادگیری ماشین، مانند رگرسیون تصادفی جنگل یا K-neighbors regressor، اکنون میتوانند به راحتی برای تکمیل تجزیه و تحلیل آب معمولی ما استفاده شوند.
آیا می توانیم به آن اعتماد کنیم؟ دقت مدل یادگیری ماشینی
چهار سال از دادههای تست در مقیاس کامل و jar برای NEWPP برای یادگیری ماشین استفاده شد که 80 درصد از دادهها (2666 نقطه داده) برای آموزش مدل و 20 درصد از دادهها (644 نقطه داده) برای آزمایش مدل استفاده شد. دقت. داده ها شامل، اما محدود به، TOC آب خام، کدورت، و پتانسیل زتا هستند. TOC آب ته نشین شده، کدورت و پتانسیل زتا. دوز ACH؛ مقدار کمک لخته سازی; مقدار کمک منعقد کننده؛ زمان؛ و دما الگوریتم یادگیری ماشین را می توان در سه حالت شبیه سازی استفاده کرد: 1) حالت ماشین حساب شیمیایی برای پیش بینی دوزهای شیمیایی؛ 2) حالت سرعت حذف برای پیش بینی TOC آب ته نشین شده و کدورت. و 3) حالت پتانسیل زتا برای پیش بینی مقدار مواد شیمیایی مورد نیاز برای دستیابی به پتانسیل زتا هدف. هنگامی که با استفاده از دادههای آزمایش 20 درصد مقایسه میشود، مدل یادگیری ماشینی بهطور دقیق کیفیت آب تهنشین شده و دوزهای شیمیایی را با محدوده R2 از 0.93 تا 0.99 پیشبینی میکند که به طور قابلتوجهی بهتر از مدلهای تجربی برازش معمولی است (شکل 3).
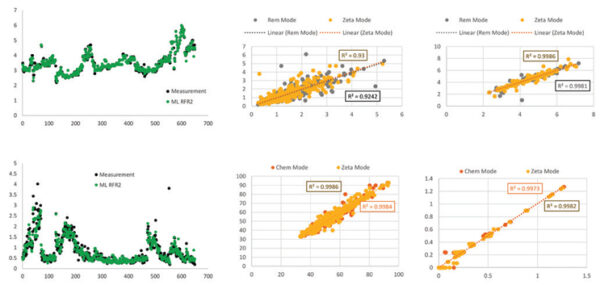
تصویر 3. مدل یادگیری ماشینی TOC و کدورت آب ته نشین شده، دوزهای ACH و دوز کمک منعقد کننده را به دقت پیشبینی میکند. (دادههای اندازهگیری شده به رنگ مشکی؛ پیشبینیهای یادگیری ماشین به رنگ سبز.)
هنگامی که دقت مدل با موفقیت نشان داده شد، ماژول یادگیری ماشین در آخرین نسخه شبیه سازهای عملیات NEWPP ادغام شد. این نوآوری با استقبال خوبی از سوی مدیران و اپراتورهای کارخانه مواجه شد. این به طور فعال برای آموزش، عیب یابی، و برنامه ریزی O&M استفاده می شود. این کارخانه روز به روز در حال جمع آوری داده های اضافی است که برای آموزش مجدد مدل یادگیری ماشین استفاده می شود. انتظار می رود که دقت مدل در طول زمان همچنان بهبود یابد.
چه کار دیگری می توانیم با آن انجام دهیم؟ سایر کاربردهای یادگیری ماشینی در تصفیه آب
به جای در نظر گرفتن آن به عنوان یک جعبه سیاه، یادگیری ماشین، زمانی که به درستی اعمال شود، مفید واقع شده است. به ویژه هنگامی که هیچ مکانیسم یا همبستگی شناخته شده ای برای پیش بینی نتایج در دسترس نیست و زمانی که تنظیم چندین عامل (در مورد بالا، دوزهای چند ماده شیمیایی) با نتایج متعدد (مانند TOC، کدورت، پتانسیل زتا و غیره) ختم می شود، راه حل خوبی است). گام منطقی بعدی برای بهبود دوقلو دیجیتال NEWPP استفاده از یادگیری ماشین برای مدلسازی فرآیند فیلتراسیون رسانهای دانهای است. انتظار میرود که این روشهای تجربی فعلی را برای تخمین کیفیت آب فیلتر شده، فرکانس شستشوی معکوس فیلتر و حجم اجرای فیلتر واحد (UFRV) بهبود بخشد. این منجر به شبیهسازی دقیقتر پوسیدگی ضدعفونیکننده و تشکیل DBP با استفاده از یک مدل مکانیکی مبتنی بر دادههای ترکیبی میشود.
کاربردهای یادگیری ماشینی در صنعت آب می تواند حتی مفیدتر از آنچه در بالا نشان داده شد باشد. همچنین میتواند برای مدلسازی عملکرد فرآیند جذب برای پیشبینی فرکانس جایگزینی رسانه برای حذف TOC یا مواد پر و پلی فلوروآلکیل (PFAS) استفاده شود. مدلسازی فرآیند غشایی برای پیشبینی فرکانسهای شستشوی معکوس غشا، شستشوی تعمیر و نگهداری و تمیز کردن در محل (CIP). و مدل کنترل پیش بینی تصفیه بیولوژیکی فاضلاب.
علاوه بر این، می توان از آن برای تکمیل مدل سازی کیفیت آب سیستم توزیع نیز استفاده کرد. شرکتهای برق اغلب سالها داده در مورد باقیماندههای کلر، تری هالومتانها (THMs) و اسیدهای هالواستیک (HAAs) در سیستم توزیع دارند. سایر داده ها نیز مرتبط هستند، از جمله کیفیت آب از هر منبع در سیستم (برمید، UV254، pH، دما، کربن[DOC] آلی محلول، و غیره)، دوز کلر در هر نقطه تزریق، و اطلاعات مورد نیاز برای تخمین سن آب و منبع. سهم در کل سیستم توزیع.
یک مدل یادگیری ماشین، که دائماً دادههای بلادرنگ را دریافت و پردازش میکند و اغلب به شیوهای خودکار بازآموزی میشود، میتواند برای مقابله با چنین پیچیدگی و افزایش ماهیت پویا عملیات سیستم توزیع مفید باشد. اغلب مسئله کمبود داده نیست، بلکه فقدان یک رویکرد تثبیت شده برای تبدیل داده ها به دانش است. برای رویارویی با این چالش، Carollo در حال کار با شرکت های آب و برق برای ایجاد خط لوله داده برای جمع آوری داده ها به صورت نیمه یا تمام اتوماتیک از منابع مختلف (SCADA، سیستم های مدیریت اطلاعات آزمایشگاهی) است. [LIMS]، دیتالوگرها، سازمان زمین شناسی ایالات متحده [USGS] وب سایت و غیره) برای تغذیه دوقلو دیجیتال. یک ماژول پردازش داده قوی نیز در Blue Plan-it ادغام شده است تا اطلاعات خام را پاکسازی، کوچک کردن، نمونهبرداری مجدد و پردازش اطلاعات خام به دادههای مفیدی که میتواند مدل را تغذیه کند، ادغام کند.
منبع: WaterOnline